Applying Live Context to your Copilot
This feature is currently in Beta and is now generally available to all users. It is only available to macOS & Windows users, with Linux support coming ASAP 🙏🏼.
Since the original launch of Pieces for Developers, we’ve been laser-focused on developer productivity. We started by giving devs a place to store their most valuable snippets of code, then moved on to proactively saving and contextualizing them. Next, we built one of the first on-device LLM-powered AI copilots in the Pieces Copilot. Now, we’re taking our obsession with contextual developer productivity to the next level with the launch of Live Context within our copilot, making it the world’s first temporally grounded copilot.
We would like to introduce Live Context in Pieces for Developers, powered by our Workstream Pattern Engine (WPE), which enables the world’s first Temporally Grounded Copilot.
Live Context elevates the Pieces Copilot, allowing it to understand your workflow and discuss how, where, and when you work. As with everything we do here at Pieces, this all happens entirely on-device and is available on macOS, Windows, and Linux. We truly believe the Pieces Copilot+ will revolutionize how you cross off your to-dos.
By using context captured throughout your workflow, Pieces Copilot+ can provide hyper-aware assistance to guide you right back to where you left off. Ask it, “What was I working on an hour ago?” and let it help you get back into flow. Ask it, “How can I resolve the issue I got with Cocoa Pods in the terminal in IntelliJ?” or “What did Mack say I should test in the latest release?” and let Pieces Copilot surface the information that you know you have, but you can’t remember where.
Pieces Copilot+ is now temporally grounded in exactly what you have been working on, which reduces the need for manual context input, enhances continuity in developer tasks, reduces context switching, and enables more natural, intuitive interactions with the Pieces Copilot.
The Workstream Pattern Engine
The Live Context in the Pieces Copilot comes from the Workstream Pattern Engine, which shadows your workflow on an operating system level. Whether you're on macOS, Windows, or Linux, your workflow will be locally captured, processed, and stored entirely on-device, where it is then available to be leveraged as Live Context within your current and future Copilot Chats. The Workstream Pattern Engine applies several on-device and real-time algorithms to this data to proactively capture the most important information as you go about your workday, wherever you are— your browser, your IDE, or your collaboration tools. Over time, the Workstream Pattern Engine learns more and more about your work and becomes increasingly helpful. It even takes context from your previous copilot chats to build on the knowledge you are capturing.
Getting Started with Live Context
Enabling/Disabling the WPE
In order to use Live Context in your conversations with Pieces Copilot, you will need to enable the Workstream Pattern Engine. You can disable it at any time, but remember that the Copilot will not be able to use Live Context from when you had it disabled.
To enable or disable the engine, head to the Machine Learning section of the Settings page of the Pieces Desktop App. You’ll see a button to enable the Workstream Pattern Engine— hit it, and you’re good to go!
Clearing Workstream Pattern Engine Data
You also can clear Workstream Pattern Engine data at any time, from a specific time range or everything currently stored. Please note that once you take this action, the Pieces Copilot will not be able to apply Live Context from the selected range.
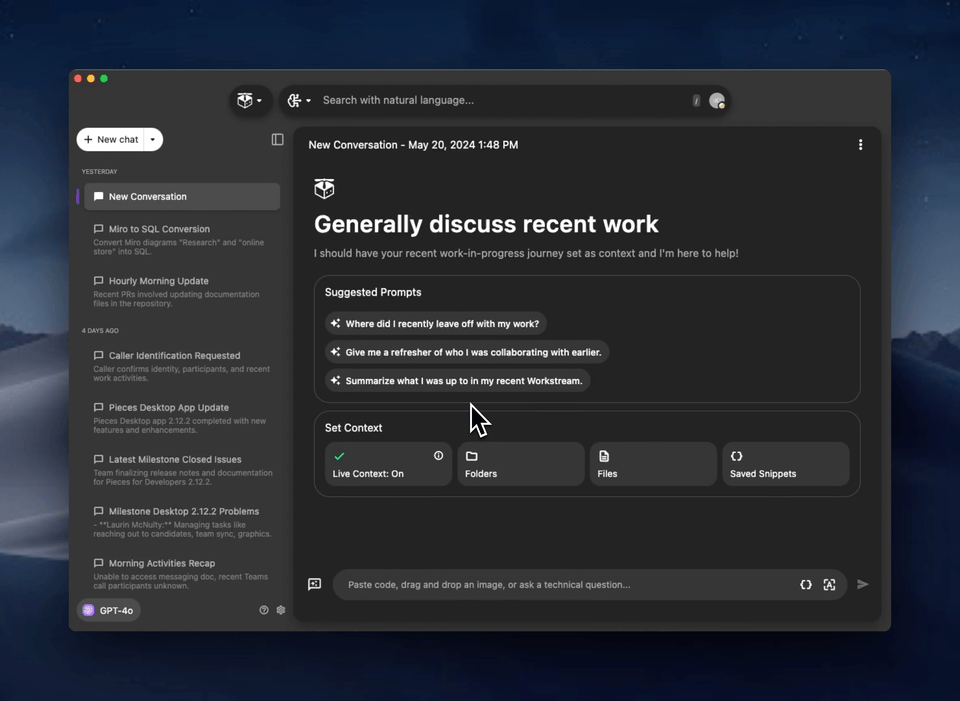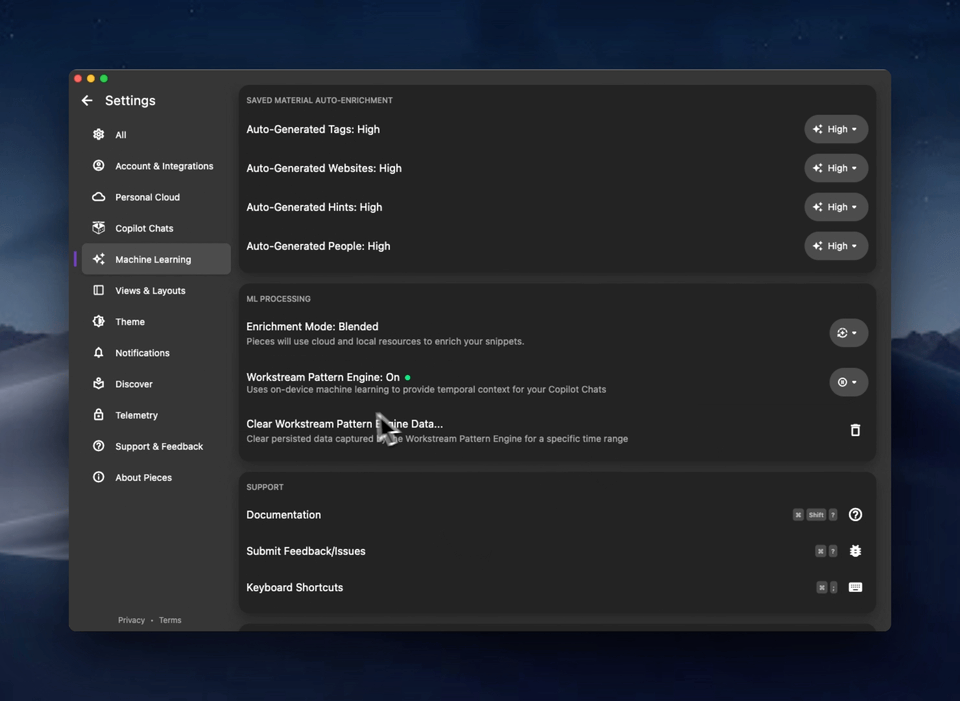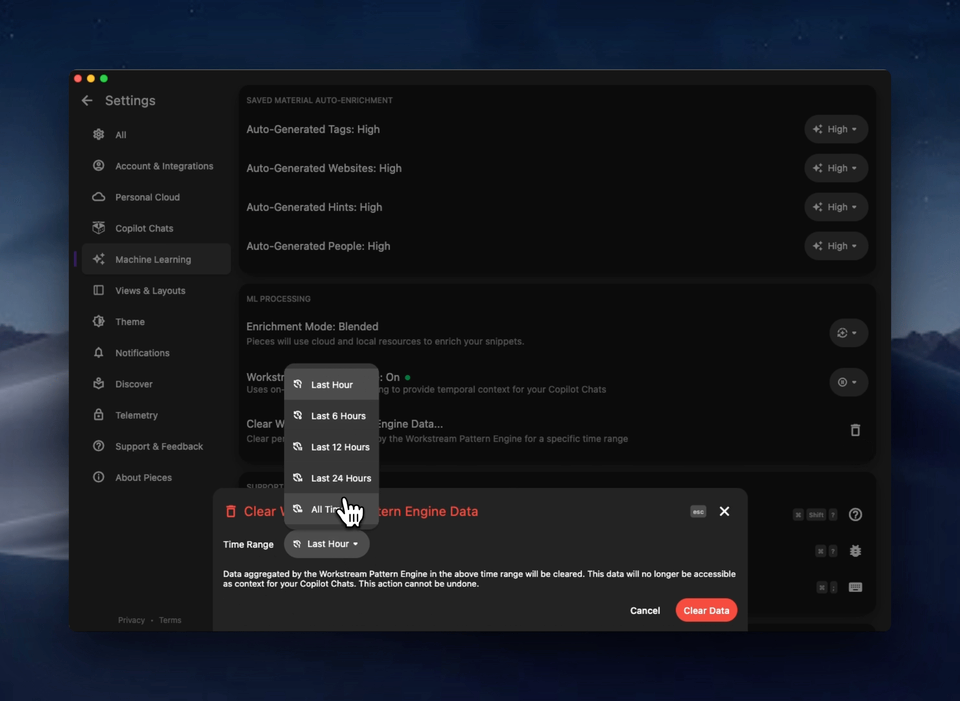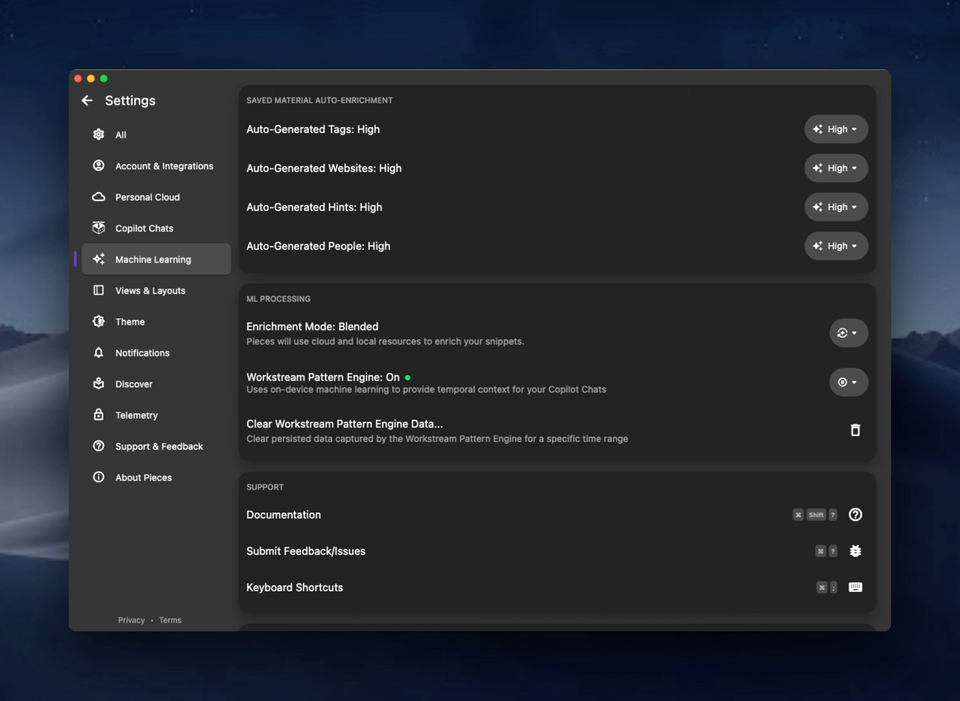
Using Live Context
Once you've enabled the Workstream Pattern Engine, go about your usual work for a few minutes, and then head to the Copilot Chats view in the Pieces for Developers Desktop App and select “New Chat.” In the “Set Context” section, tap the option labeled “Live Context." Like before, you can leverage any of our available models, on-device or cloud, to engage with Live Context in the Pieces Copilot, and you can use it across your toolchain to carry on conversations in your favorite IDE and browser.

The Workstream Pattern Engine must be turned on to use Live Context. We’ve made this super easy to do from wherever you’re getting started.
You can add additional context to further tailor the conversation if you’d like.
Permissions
For macOS users only, you will need to update Pieces’ permissions in order to use Live Context.
You can also manually update this by adding and enabling Pieces OS in the following settings:
Privacy & Security > Accessibility
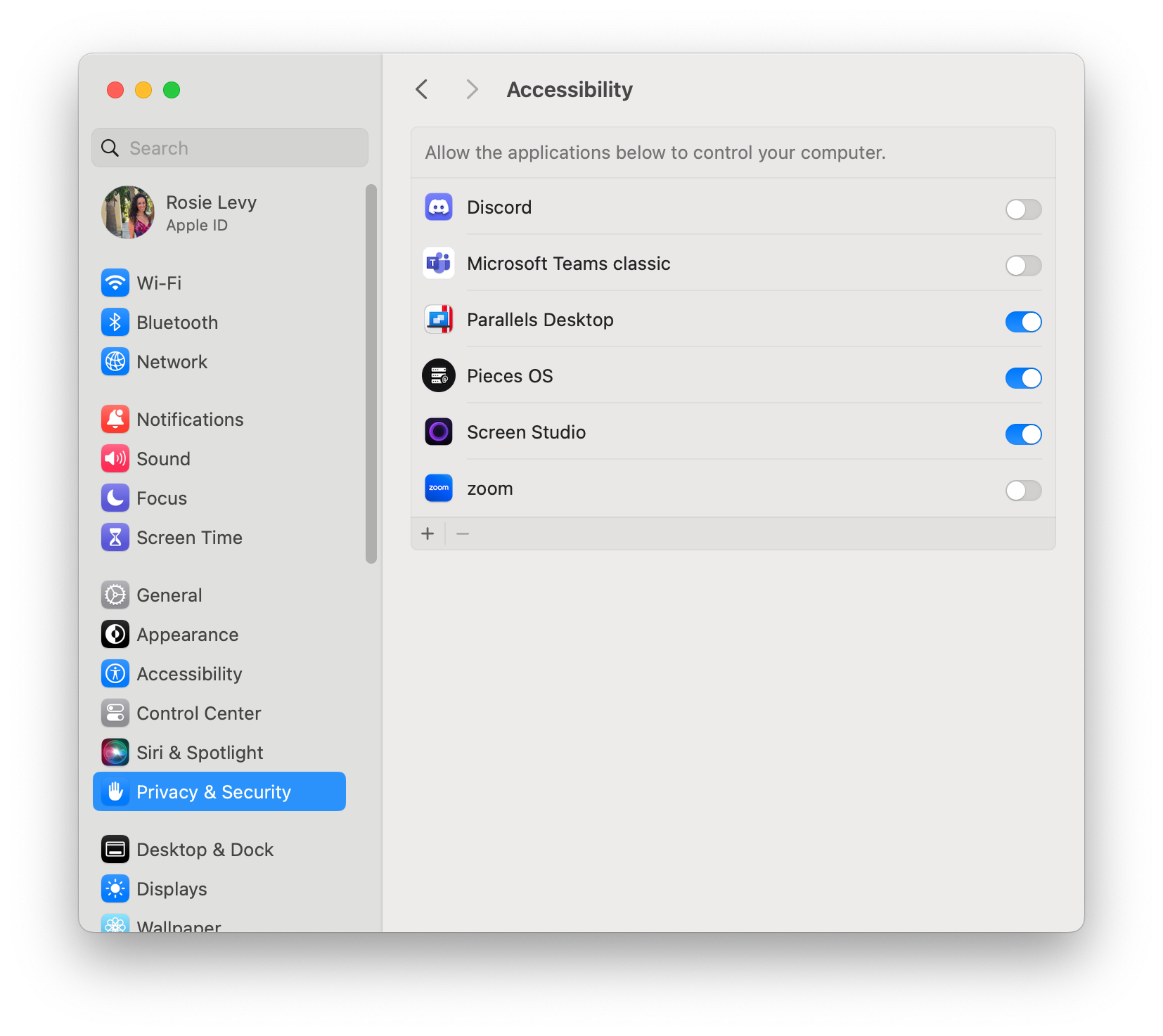
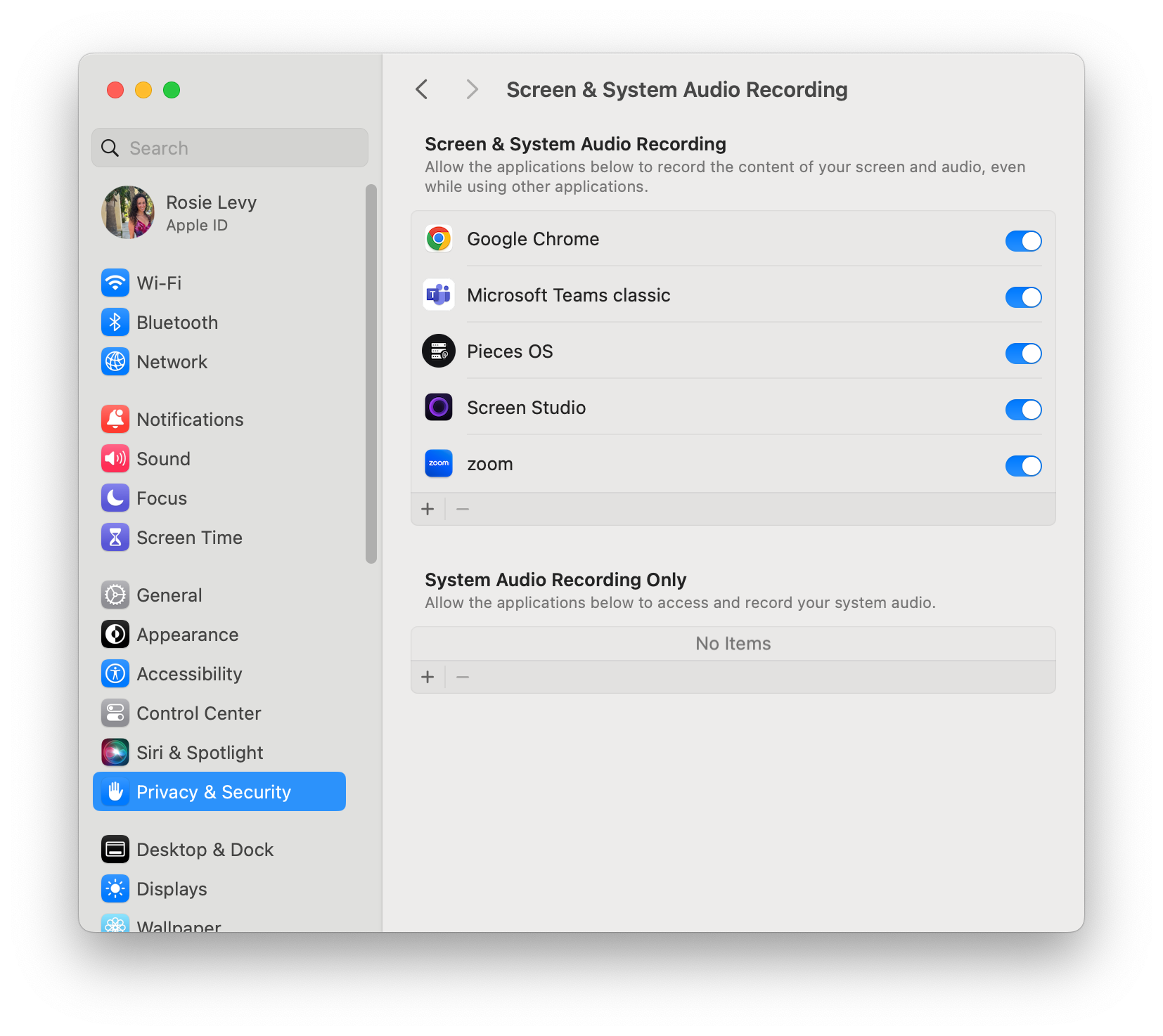
Privacy & Security > Screen and System Audio Recording
Live Context Use Cases
We recommend clicking around your workflow between chats, websites, emails, code, etc., while the WPE is running before asking a question to get the most value out of it (i.e., data capture).
Best Practices
Prompting
As with any interaction with an LLM, good prompting practices will improve your experience greatly. Use specifics like application and file names whenever possible, and if you aren't getting the answer you are looking for, try rephrasing or switching to a different LLM model. If the Pieces Copilot tells you it does not have workstream context related to your prompt, try flipping back to the source of that context on your screen, wait for a few seconds to allow for processing, and then ask again.
Here are a few real prompts and use cases captured from the Pieces Team and Early Access users:
Workflow Assistance
- "What task should I do next?"
- "What did Mark say about requests to the xyz api in slack?"
- "Based on the given workflow context, have I performed all the necessary release chores in order to release our plugins for VS Code, JetBrains, Obsidian, and JupyterLab? In general, I need to bump their versions, update the changelogs, and make sure to support the latest version of the copilot package."
Research
- Review a new package or new API and ask, "How can I use the Lua SDK to call the version endpoint?"
- Review a support forum that had a specific solution to a difficult problem and ask the Pieces Copilot to apply it to the problem I am trying to solve.
- Review a research paper and have the Pieces Copilot summarize it for me.
- "Can you summarize the readme file from the pieces_for_x repo?"
- "Can you explain the usage of the
useEffectfunction in the React library?"
"Coding"
- “How can I resolve the issue I'm experiencing in the handleQGPTStreamEvent function in IntelliJ?”
- “Implement the handleQGPTStreamEvent function according to the comment about the function definition.”
- “How should I adjust the initCopilot function given the global state implementation details outlined in Obsidian?”
- “How can I adjust the incrementalRender function to perform better when the difference between original and updated is very large?”
- "Generate a script in python using the function I saw on W3Schools to create a variable named xyz"
Interaction with Language Models (LLM)
- Cloud LLM: If you are using a cloud-based LLM, the data identified as relevant is sent to the cloud LLM for processing.
- Local LLM: If you are using a local LLM, the data remains on your device, ensuring that all processing happens locally without any data leaving your device.
Data and Privacy
Your workstream data is captured and stored locally on-device. At no point will anyone, including the Pieces team, have access to this data unless you choose to share it with us.
The Workstream Pattern Engine triangulates and leverages on-task and technical context across developer-specific tools you're actively using. The bulk of the processing that occurs within the Workstream Pattern Engine is filtering, which utilizes our on-device machine learning engines to ignore sensitive information and secrets. This enables the highest levels of performance, security, and privacy.
Lastly, for some advanced components within the Workstream Pattern Engine, blended processing is required to be set via user preferences, and you will need to leverage a cloud-powered Large Language Model as your copilot’s runtime.
That said, you can leverage Local Large Language Models, but this may reduce the fidelity of output and requires a fairly new machine (2021 and newer) and ideally a dedicated GPU for this. You can read this blog for more information about running local models on your machine.
As always, we've built Pieces from the ground up to put you in control. With that, the Workstream Pattern Engine may be paused and resumed at any time.